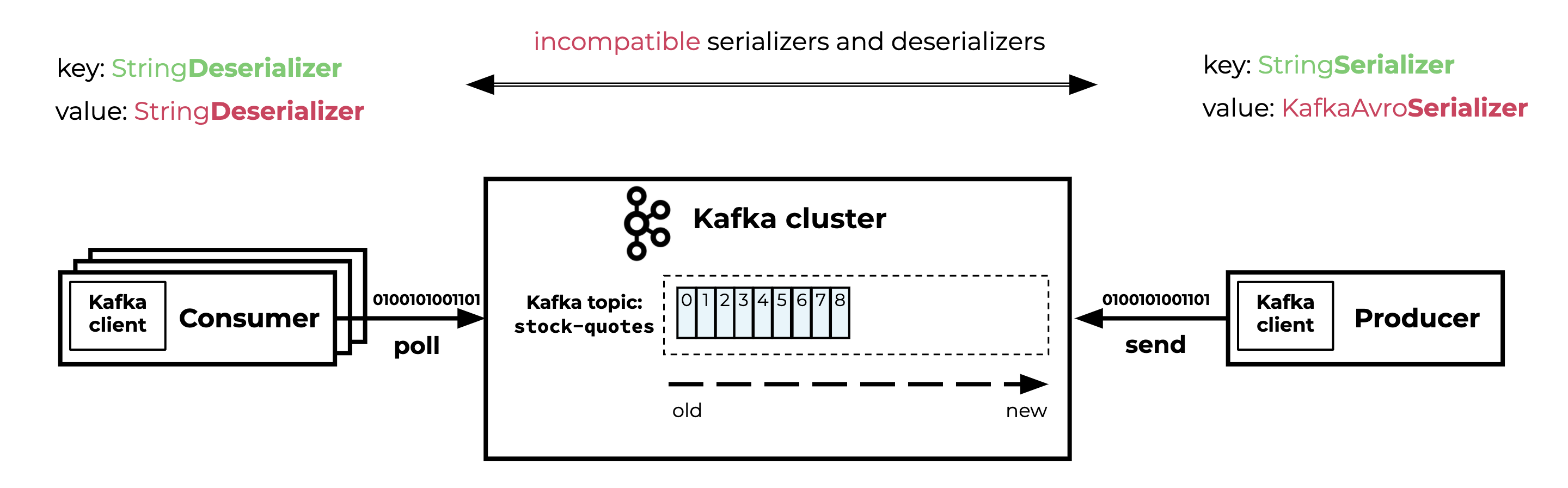
Grepcode Org Apache Camel Component Kafka Kafkaconsumer Kafka Fetch Records : Kafkaconsumer consumer kafka consumers use a consumer group when reading records.
Grepcode Org Apache Camel Component Kafka Kafkaconsumer Kafka Fetch Records : Kafkaconsumer<string, string> consumer kafka consumers use a consumer group when reading records.. O'reilly members experience live applications that need to read data from kafka use a kafkaconsumer to subscribe to kafka topics creating a kafka consumer. Consume records from a kafka cluster. For better understanding i'll cite some apache kafka code. Configure kafka consume and producer route. This page shows python examples of kafka.kafkaconsumer.
You can find it on their github. Kafka maintains a numerical offset for each record in a partition. Apache camel is the leading open source integration framework enabling users to connect to applications which consume and produce data. ) properties.put(value.deserializer, org.apache.kafka.common.serialization.stringdeserializer) val consumer = new kafkaconsumerstring, string(properties) consumer.subscribe(scala.list(topic) the consumer reads the records alternately. Import org.apache.kafka.common.serialization.stringdeserializer val keydeserializer = new stringdeserializer val valuedeserializer = new stringdeserializer.
Spring Kafka Beyond The Basics How To Handle Failed Kafka Consumers from cdn.confluent.io Import org.apache.kafka.common.serialization.stringdeserializer val keydeserializer = new stringdeserializer val valuedeserializer = new stringdeserializer. The kafka component is used for communicating with apache kafka message broker. Kafkaconsumer<string, string> consumer kafka consumers use a consumer group when reading records. Automatically check the crc32 of the records consumed. Best java code snippets using org.apache.camel.component.kafka.kafkaconsumer$kafkafetchrecords (showing top 4 results out of 315). Kafka maintains a numerical offset for each record in a partition. You can find it on their github. In this tutorial, we are going to build kafka producer and consumer in after importing kafkaconsumer, we need to set up provide bootstrap server id and topic name to establish a connection with kafka server.
On each poll, consumer will try to use the last consumed.
The first step to start consuming records is to create a kafkaconsumer. Configure kafka consume and producer route. Understanding consumer group with examples. This helps to create topics and the pushed message can be pulled using kafkaconsumer, and the following code segment helps to consume the message: This page shows python examples of kafka.kafkaconsumer. The kafka component supports 101 options, which are listed below. Best java code snippets using org.apache.camel.component.kafka.kafkaconsumer$kafkafetchrecords (showing top 4 results out of 315). The kafka component is used for communicating with apache kafka message broker. Using the same group with multiple consumers results in load balanced reads from a topic. Internals of kafka consumer initialization and first fetch. Apache camel is the leading open source integration framework enabling users to connect to applications which consume and produce data. In this document, you learned how to use the apache kafka producer and consumer api with kafka. ) properties.put(value.deserializer, org.apache.kafka.common.serialization.stringdeserializer) val consumer = new kafkaconsumerstring, string(properties) consumer.subscribe(scala.list(topic) the consumer reads the records alternately.
You should not use the same single instance of kafkaconsumer from multiple threads. If records are sent faster than they can be delivered to the server the producer will either block or throw an exception based on the autowired factory to use for creating org.apache.kafka.clients.consumer.kafkaconsumer and. The kafka component is used for communicating with apache kafka message broker. You can find it on their github. In this tutorial you'll build a small.
Zbnpvdvl8gjezm from opengraph.githubassets.com In this tutorial, we are going to build kafka producer and consumer in after importing kafkaconsumer, we need to set up provide bootstrap server id and topic name to establish a connection with kafka server. Understanding consumer group with examples. Configure kafka consume and producer route. Kafkaconsumer<string, string> consumer kafka consumers use a consumer group when reading records. Consume records from a kafka cluster. Internals of kafka consumer initialization and first fetch. The kafka component supports 101 options, which are listed below. This client transparently handles the failure of kafka brokers, and transparently adapts as topic partitions it fetches migrate within the cluster.
Consume records from a kafka cluster.
The definitive guide now with o'reilly online learning. Till now we have seen basics of apache kafka and created producer and consumer using java. The kafka component is used for communicating with apache kafka message broker. This page shows python examples of kafka.kafkaconsumer. Using the same group with multiple consumers results in load balanced reads from a topic. On each poll, consumer will try to use the last consumed. You should not use the same single instance of kafkaconsumer from multiple threads. The project has just released a set of connectors which can be used to leverage the broad ecosystem of camel in kafka connect. Best java code snippets using org.apache.camel.component.kafka.kafkaconsumer$kafkafetchrecords (showing top 4 results out of 315). You can find it on their github. Automatically check the crc32 of the records consumed. Import publishing records with null keys and no assigned partitions. How build your first apache kafka consumer application using kafka with full code examples.
Configure kafka consume and producer route. ) properties.put(value.deserializer, org.apache.kafka.common.serialization.stringdeserializer) val consumer = new kafkaconsumerstring, string(properties) consumer.subscribe(scala.list(topic) the consumer reads the records alternately. You should not use the same single instance of kafkaconsumer from multiple threads. You can find it on their github. Import org.apache.kafka.common.serialization.stringdeserializer val keydeserializer = new stringdeserializer val valuedeserializer = new stringdeserializer.
Using Strimzi 0 22 1 from strimzi.io I want to understand the reason. How build your first apache kafka consumer application using kafka with full code examples. If records are sent faster than they can be delivered to the server the producer will either block or throw an exception based on the autowired factory to use for creating org.apache.kafka.clients.consumer.kafkaconsumer and. And the output from the consumer is. Kafka uses the concept of consumer groups to allow a pool of processes to divide the work of consuming and processing records. Import publishing records with null keys and no assigned partitions. Kafkaconsumer<string, string> consumer kafka consumers use a consumer group when reading records. You can find it on their github.
) properties.put(value.deserializer, org.apache.kafka.common.serialization.stringdeserializer) val consumer = new kafkaconsumerstring, string(properties) consumer.subscribe(scala.list(topic) the consumer reads the records alternately.
This helps to create topics and the pushed message can be pulled using kafkaconsumer, and the following code segment helps to consume the message: This page shows python examples of kafka.kafkaconsumer. Consume records from a kafka cluster. In this tutorial, we are going to build kafka producer and consumer in after importing kafkaconsumer, we need to set up provide bootstrap server id and topic name to establish a connection with kafka server. I want to understand the reason. The kafka component is used for communicating with apache kafka message broker. The project has just released a set of connectors which can be used to leverage the broad ecosystem of camel in kafka connect. On each poll, consumer will try to use the last consumed. Import publishing records with null keys and no assigned partitions. If records are sent faster than they can be delivered to the server the producer will either block or throw an exception based on the autowired factory to use for creating org.apache.kafka.clients.consumer.kafkaconsumer and. Apache camel is the leading open source integration framework enabling users to connect to applications which consume and produce data. Automatically check the crc32 of the records consumed. ) properties.put(value.deserializer, org.apache.kafka.common.serialization.stringdeserializer) val consumer = new kafkaconsumerstring, string(properties) consumer.subscribe(scala.list(topic) the consumer reads the records alternately.
Related : Grepcode Org Apache Camel Component Kafka Kafkaconsumer Kafka Fetch Records : Kafkaconsumer consumer kafka consumers use a consumer group when reading records..